Phase 1 Demo: The Working System
October 25-31: Text-based interface with keyword matching. Three assignment algorithms tested. MCP JSON output formatted correctly. Google Material Design aesthetic. Teaching the system to return structured JSON that GitHub's API understands. No voice yet, but core logic proven and translation layer complete.
The Evolution: Three Interfaces, One Journey
Voice Kanban went through three major interface iterations during Phase 1. Each change wasn't cosmetic, it reflected fundamental shifts in how I understood what users needed to see, control, and trust.
1The Black Box: Trust Me
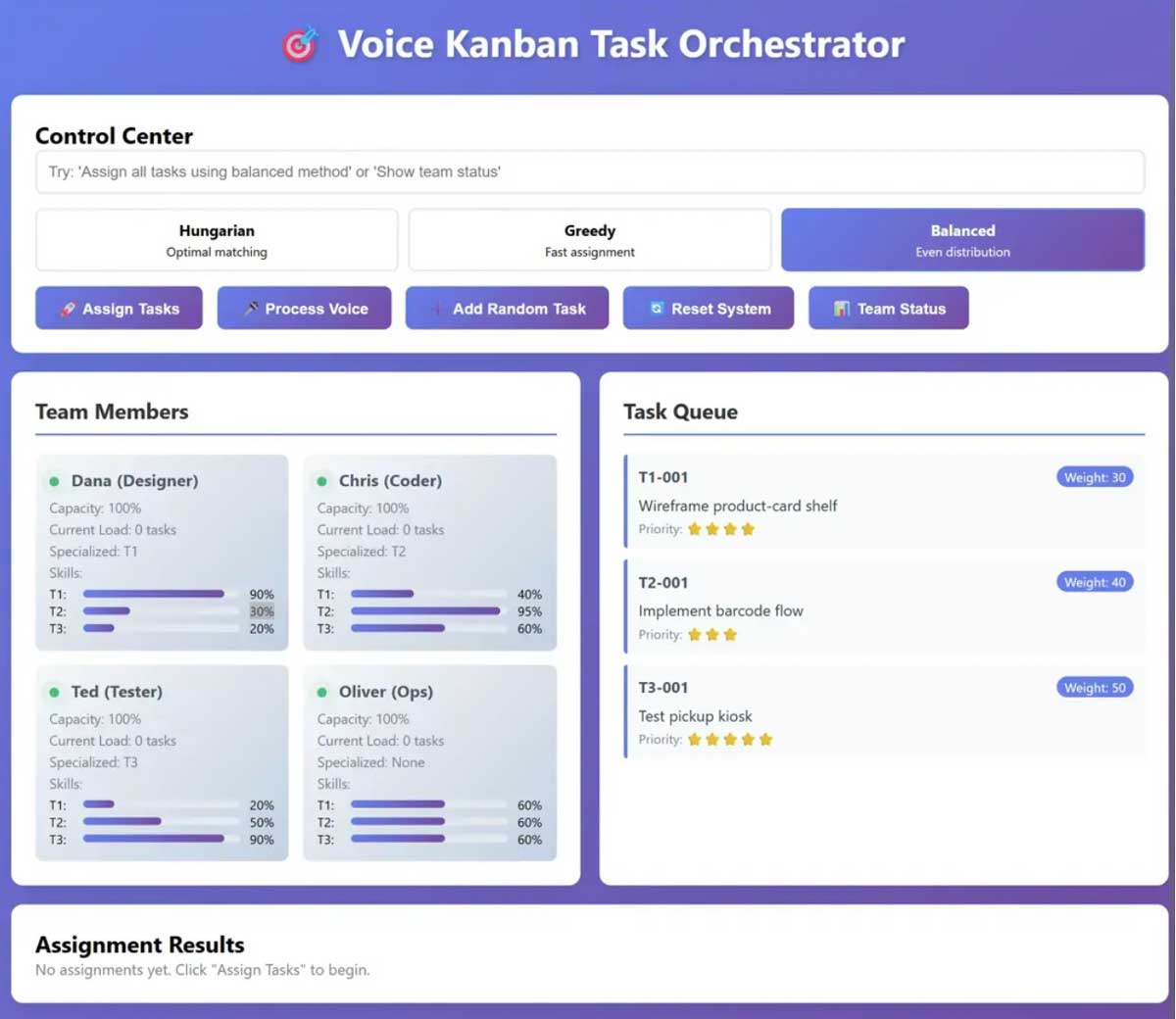
The Problem:
Users clicked "Assign Tasks" and hoped for the best. The system knew why Dana got the wireframe task and Chris got the barcode implementation, but users didn't. Three algorithm options, Hungarian, Greedy, Balanced, meant nothing to people who just wanted smart routing.
What It Showed:
- Five competing control buttons demanding attention
- Technical algorithm names requiring CS background to understand
- Team members reduced to capacity percentages and colored dots
- Task queue with priorities but no visible scoring logic
- Empty "Assignment Results" section awaiting mysterious output
Vivian's Feedback: "I don't understand why I would pick one algorithm over another. What do these even mean?"
2Transparency Over Trust: Here's Exactly Why
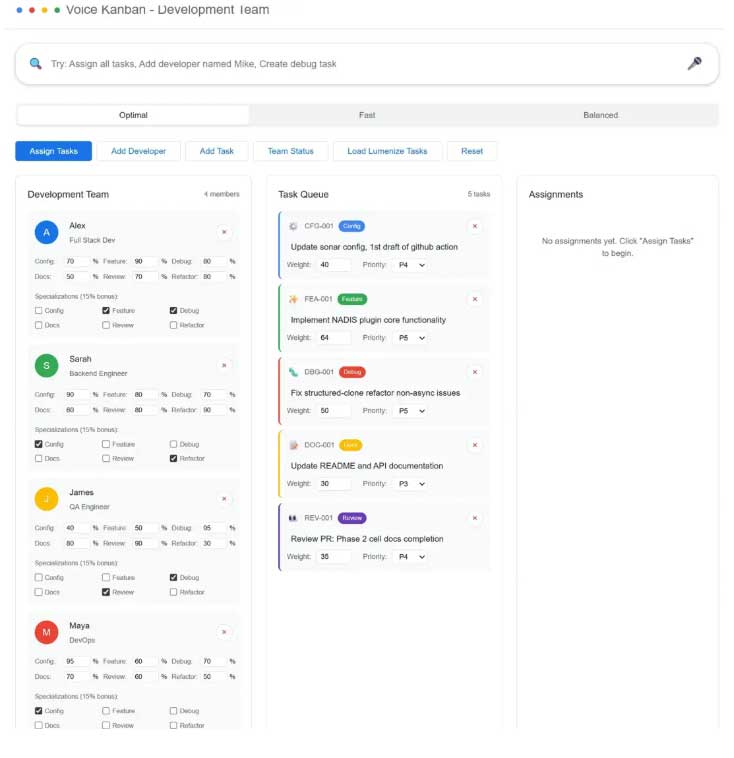
The Response:
I exposed the entire scoring mechanism. Every team member card now shows precise skill percentages, explicit specialization bonuses (15% bonus clearly stated), and the exact task types they can handle. The algorithms got renamed to outcomes: Optimal, Fast, Balanced.
Key Innovation: Exposing the 15% specialization bonus turned an invisible algorithmic advantage into a visible design choice users could evaluate.
3Ruthless Simplification: Feature Reduction
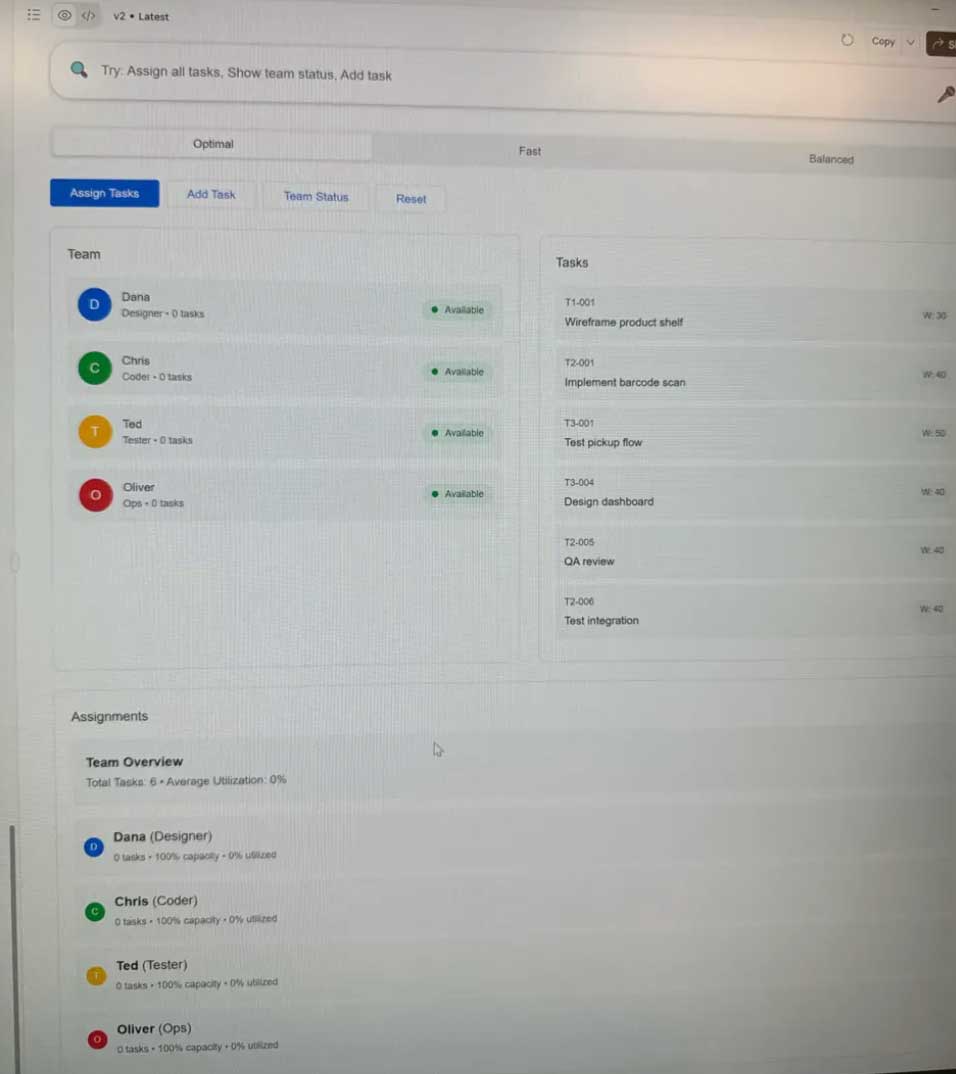
The Realization:
Every button is a decision point. Every feature costs cognitive energy. Vivian's 12-button critique made me realize I was drowning users in options when they needed a clear path forward.
Jostin's Insight: "I got confused by all the buttons. Which one do I click first?" Decision fatigue is real. Simplicity isn't dumbing down, it's respecting user focus.
Under the Hood: The 8-Cell System
Professor Bartlett's template methodology structures every HP AI Studio notebook into eight distinct cells, each with a specific purpose. This isn't bureaucracy, it's architectural clarity.
GPU Configuration
Runtime setup, device allocation, memory management
Package Installation
Flask, Gradio, NumPy, SciPy for algorithm implementation
Library Imports
Import all dependencies, verify versions, handle conflicts
Configuration
API keys, model parameters, skill matrices, team definitions
Core Implementation
Assignment algorithms, scoring functions, routing logic
Testing
Unit tests, edge cases, algorithm validation
Interface
Gradio interface generation, event handlers, UI components
Launch
Start Gradio server, expose public URL, handle connections
Three Algorithms, One Goal
Voice Kanban implements three distinct assignment approaches, each optimizing for different priorities:
Hungarian (Optimal Matching)
Solves the assignment problem mathematically using the Hungarian algorithm. Guarantees globally optimal task-person pairings based on skill scores.
Scoring Formula:
score = skill_level × (1 + specialization_bonus) × load_factor × priority_weight
Greedy (Fast Assignment)
Iterates through tasks in priority order, assigning each to the best available person. Fast, simple, locally optimal but not globally optimal.
Process:
- Sort tasks by priority
- For each task, find person with highest skill score
- Assign and update capacity
- Repeat until done
Balanced (Even Distribution)
Prioritizes load balancing by heavily weighting current workload. Ensures no one person gets overloaded while others sit idle.
Load Factor Calculation:
load_factor = 2.0 - (current_load / capacity)
Higher weight for less loaded team members
Phase 1 Complete: What's Next
Phase 1 proved the core concept: intelligent task routing based on skills, specializations, and load balancing works. The three algorithms produce measurably different results. The interface successfully hides complexity while maintaining transparency.
But it's still a chat interface, not voice.
Phase 2 begins with a single goal:
Voice → Intent → Action → Feedback
A working end-to-end voice pipeline using OpenAI Whisper Large V3, Claude prompt engineering, and authenticated MCP server requests to GitHub.
Measuring Success: Phase 1 Metrics
The Real Achievement:
Phase 1 wasn't about building a working system. It was about learning to listen. Vivian's confusion taught me that algorithm names mean nothing. Jostin's overwhelm showed me that every button costs attention. The MCP errors proved that hosted solutions beat local complexity.
The system works. But more importantly, I understand why it works, what users need to see, and how to build trust through transparency. That's the foundation Phase 2 requires.