Building From Ground Zero: The Five-Phase Pipeline
From empty notebooks to working voice orchestration
October 16: Staring at an empty HP AI Studio workspace. No code. No models. No infrastructure. Just GPU resources and the challenge: build a voice-controlled AI task orchestrator from scratch in 20 weeks. The professor's guidance was clear: "Hide complexity inside simplicity." Break it into phases. Prove each piece works before moving forward.
The Architecture: Three Layers
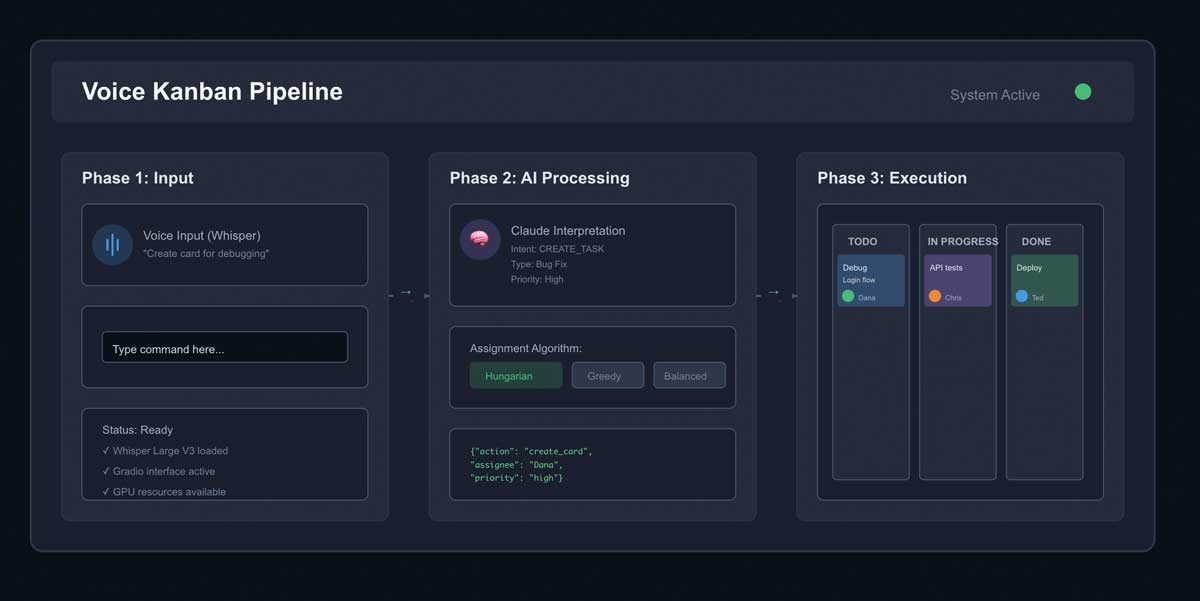
Before diving into phases, we needed architectural clarity. Voice Kanban operates across three distinct layers, each with its own responsibility:
HP AI Studio: The Orchestrator
The top layer. Manages GPU resources, hosts models, coordinates between components. Ubuntu 24 workspace with Jupyter notebooks following the 8-cell template. This is where everything lives and breathes.
Claude + Whisper: The Reasoning Layer
The intelligence. Whisper Large V3 converts voice to text. Claude interprets intent, makes routing decisions, suggests task assignments. This is where natural language becomes structured commands.
GitLab Kanban MCP: The Executor
The action layer. Takes structured commands and executes them through MCP (Model Context Protocol) servers. Creates cards, moves tasks, updates status. This is where decisions become reality.
Three layers. Each needed to work independently before integration. That insight drove the phase-based approach.
Phase 1: Local Setup (Weeks 1-2)
Goal: Prove the pipeline exists. Voice goes in, text comes out.
Started with Whisper. The professor's 8-cell template made this manageable: Cell 1 handles GPU configuration, Cell 2 installs packages, Cell 3 imports libraries. By Cell 6, we were running actual model code.
First hurdle: audio library errors.
ModuleNotFoundError: No module named 'pyaudio'
OSError: PortAudio library not found
RuntimeError: Failed to initialize audio backend
Spent days fighting audio drivers. Tried PyAudio, SoundDevice, alternative backends. Nothing worked consistently on HP AI Studio's Ubuntu environment.
Then the breakthrough: simplify. Don't start with voice. Start with chat.
Built a text-based interface using Gradio. Proved the full pipeline: input → Claude interpretation → MCP JSON output → (eventual) API execution. Voice could be Phase 2. First, prove the concept works.
Phase 1 Deliverables
- ✓ HP AI Studio workspace configured with GPU access
- ✓ Jupyter notebook following 8-cell template methodology
- ✓ Gradio interface for text-based command testing
- ✓ Keyword matching system for command parsing
- ✓ MCP JSON output generation (not yet executed)
Phase 2: AI Services (Weeks 3-5)
Goal: Add intelligence. Make the system understand intent, not just keywords.
The keyword matching from Phase 1 was brittle. "Create a card for debugging the login flow" worked. "We need to track that authentication bug" didn't.
Integrated Claude API for semantic understanding. Natural language → structured intent → API actions.
Second hurdle: MCP confusion.
I thought MCP servers had to be installed locally. Spent a week researching how to run MCP servers on HP AI Studio. Downloaded GitHub repositories. Read documentation about localhost endpoints.
October 22: The professor clarified everything in one message:
"What you want is something that's not a project on GitHub. Rather, you want something like a press release that talks about an existing Kanban board vendor exposing/releasing/announcing an MCP server for their Kanban board. GitHub has one for Issues which are the cards on a GitHub Project Kanban Board."
Breakthrough moment. MCP servers are hosted by the service providers. GitHub offers api.githubcopilot.com with MCP endpoints. Trello and Jira would have their own. We don't install them, we configure their URLs.
This unblocked everything. Shifted focus from infrastructure to integration.
The Three Assignment Algorithms
With Claude integration working, implemented three approaches to task assignment:
- Hungarian Algorithm: Mathematically optimal assignment minimizing total cost. Slow (O(n³)) but guarantees global optimum.
- Greedy Assignment: Fast heuristic (O(n²)) selecting best immediate match. Locally optimal at each step.
- Balanced Flow: Hybrid approach balancing skill match, specialization, load distribution, and priority across four weighted dimensions.
Gradio interface lets users select which algorithm to use at runtime. Each produces different assignments based on its optimization criteria.
Phase 3: Deploy to HP AI Studio (Weeks 5-7)
Goal: Make it persistent. Turn prototype into deployed system.
Current status: Early in this phase.
The workspace environment is ephemeral. Create a file, close the workspace, it's gone. Everything lives in memory until explicitly saved to /home/claude and then moved to /mnt/user-data/outputs.
Deployment means:
- Configuring persistent endpoints for Whisper and Claude models
- Setting up Flask → Gradio → Jupyter integration for web access
- Managing frontend environment variables for Google Material Design UI
- Implementing load balancing for multiple simultaneous users
Critical lesson learned: Always maintain 100GB free storage. When the physical hard drive fills, Ubuntu behaves erratically, can't write data, system becomes unstable. Storage management isn't optional.
Phase 4: Verification (Weeks 7-8)
Goal: Prove it works. Measure performance, catch edge cases.
Haven't reached this phase yet, but the plan is clear:
Evaluation Strategy
- Latency Testing: Measure voice → action completion time. Target: under 3 seconds for command execution.
- Dataset Validation: Use TaskBench for project management terminology. Test against speech command datasets.
- Algorithm Comparison: Run 100 test scenarios through Hungarian, Greedy, and Balanced algorithms. Compare outcomes.
- Prompt Engineering Evals: Test multiple prompt versions using CLEAR framework. Measure interpretation accuracy.
- Edge Case Handling: Ambiguous commands, conflicting priorities, overloaded team members. Does it fail gracefully?
The professor's emphasis: "Evals are how you know if your prompts are getting better or worse. Without structured testing, you're just guessing."
Phase 5: Documentation (Weeks 8-10)
Goal: Capture the learning. Failures, successes, implications.
November 13: The "first red flag alarm." Professor checked blogs and found most behind schedule, including mine.
"Your final piece of work for this class is not a product. It is a portfolio of learning. Failures have as much weight in terms of academics as successes do. You need to start tracking and cataloging your work."
The wake-up call. Documentation isn't post-hoc summary. It's continuous reflection on the development process.
Shifted strategy: video logs. Faster than writing. More honest reflections. Screen recordings showing what works and what breaks. Audio narration explaining the why behind decisions.
Ideate → Create → Reflect
The course methodology has equal academic weight at all three stages:
- Ideate: Map the architecture. Break down the puzzle pieces. Identify what you need to build.
- Create: Pick one piece. Try to make it work. Iterate until it functions or you understand why it doesn't.
- Reflect: Document the attempt. Catalog failures and successes. Most importantly: identify implications, what comes next.
This cycle repeats. Each reflection feeds the next ideation. Each creation attempt surfaces new questions.
The Unknown Unknowns
Everyone messes this up. We plan to the deadline. "Everything needs to be done by Thursday of Week 10." No buffer for chaos.
The lesson from software development veterans: internal deadline should be Tuesday of Week 10. That gives 48 hours for the unexpected:
- Models that suddenly stop responding
- API rate limits you didn't know existed
- Files that get corrupted
- Gradio interfaces that break on deployment
- Audio drivers that worked yesterday but not today
You can't predict what will break. But you can predict something will break. Buffer time isn't optional.
What Voice Adds (Coming in Phase 2)
Current system works through text. Type a command, get a response. Functional but not transformative.
Voice integration changes the interaction model:
Voice as Differentiator
- Hands-Free Operation: Designers can update boards while working in Figma. Developers can create tasks without leaving code.
- Accessibility: Supports team members with mobility constraints or visual impairments. Alternative input method.
- Natural Interaction: Speaking is faster than typing. "Move card to testing" vs. clicking through UI menus.
- Mobile Context: Update workflow while away from desk. Works in meetings, during stand-ups, in transit.
Whisper Large V3 will handle the speech-to-text. Then the existing pipeline kicks in: Claude interprets intent, generates MCP commands, executes actions.
The architecture supports this. We built chat-first to prove the pipeline. Voice is the final layer, not the foundation.
Key Learnings from Ground Zero
Building from scratch revealed insights that reading documentation never could:
1. Simplicity beats ambition early. Chat interface before voice. Keyword matching before semantic understanding. Prove the pipeline exists before optimizing it.
2. Infrastructure confusion is real. MCP local vs. hosted blocked progress for a week. One clarifying conversation unblocked everything.
3. Documentation can't be post-hoc. Attempting to write blogs after building reveals how much context was lost. Real-time reflection captures the why.
4. Phase gates force decisions. Can't move to Phase 3 until Phase 2 proves functional. Prevents half-built systems.
5. Buffer time isn't pessimism. Unknown unknowns will emerge. 48-hour buffer is the minimum safety net.
6. The 8-cell template is brilliant. Standardized structure makes reproduction easier. Every notebook follows the same pattern: GPU config → install → import → configure → implement → test → interface → launch.
What's Next
We're at the transition point. Phase 1 delivered proof of concept. Phase 2 added intelligence. Phase 3 deployment begins now.
Immediate priorities:
- Persistent Model Endpoints: Whisper and Claude need to stay available, not reload on every request.
- Actual API Integration: Currently generating MCP JSON. Need to execute those commands against real GitHub/Trello/Jira APIs.
- Voice Integration Retry: Revisit Whisper with better understanding of audio backends. Chat proved the pipeline; now add voice.
- Bottleneck Detection: Implement queue monitoring. Surface when testing backs up, when review is blocked.
- Continuous Documentation: Weekly video logs. Screen recordings of failures. Reflections on implications.
The Professor's Wisdom
Throughout this ground-zero build, one piece of guidance kept resurfacing:
"Hide complexity inside simplicity. Don't try to solve everything at once. Pick one piece. Make it work. Then pick the next piece."
That's what made this possible. Not grand architecture diagrams. Not comprehensive planning documents. Just: pick a piece, make it work, document what happened, pick the next piece.
Five phases. Each builds on the previous. Each proves something specific works before moving forward.
From empty workspace to working AI orchestrator. One phase at a time.
Conclusion
Ground zero was intimidating. Blank notebooks. No models. No infrastructure. Just GPU resources and a goal.
Five phases made it manageable. Each phase had clear deliverables. Each phase proved something specific worked.
Local Setup: Pipeline exists. Text goes in, structured commands come out.
AI Services: Intelligence added. Natural language understood. Three assignment algorithms implemented.
Deployment: Making it persistent. Currently in progress.
Verification: Proving it works. Coming soon.
Documentation: Capturing the learning. Always ongoing.
The system works. Not because we planned perfectly. Because we built incrementally, tested constantly, and documented everything.
From ground zero to Phase 2 complete. Three phases to go.
One piece at a time.